嗯哼~坑爹的保护成员果然有个坑爹的来历。作为 C++ 之父的 Bjarne Stroustrup 大叔在他的大作 The Design and Evolution of C++ 中写道:(以下引自中文版《C++ 语言的设计和演化》,第 13.9 节)
在 Release 1.0 推出后不久,Mark Linton 顺便到我的办公室来了一下,提出了一个使人印象深刻的请求,
要求提供第三个控制层次,一边能直接支持斯坦福大学正在开发的 Interviews 库中所使用的风格。我们一
起揣摩,创造出单词 protected 以表示类里的一些成员,它们对于这个类和它的派生类“像公用的”,而对其
他地方就“像私用的”。
Mark 是 Interviews 的主要设计师。它的有说服力的争辩是基于实际经验和来自真实代码的实例。他论证
说,保护数据对于设计一个高效的可扩充的 X 窗口工具包是最关键的东西,而可能替代保护数据的其他方式
都因为低效、难以处理在线界面函数或者使用数据公开等等,因而是无法接受的。
…(略)…
大约五年之后,Mark 在 Interviews 里禁止了保护数据成员,因为它们已经变成许多程序错误的根源 …(略)… 实际上,我对 protected 的关心正在于它将导致使用一个基类变得太容易,就像人们可能因为懒惰而使用全局数据一样。
…(略)…
保护成员是 Release 1.2 引进的,保护基类最早是在 ARM 里描述的,Release 1.2 提供了它。回过头看,我认为 protected 是“好的论据”和时尚战胜了我的更好的判断和经验规则,使我接受新特征的一个例子。
话说我能顺便吐槽下这悲催的中文翻译么?最后一段完全不是翻给地球人看的嘛 :P
前情提要
Lua 通过一个虚拟栈与 C 的交互,正数索引自底向上取值,负数索引自顶向下取值。
Lua 中的 Table(表)结构可以使用任何数据作为 key 进行取值。使用 C API 访问 Table 中的元素有两种方法:
lua_getglobal(L, t);
lua_pushinteger(L, k); -- 这里可以换成其它类型的 lua_pushXXXX(L, k) 压数据到栈顶作key
lua_gettable(L, -2);
lua_getglobal(L, t);
lua_getfield(L, -1, k);
在结束时,栈上的情况均为:栈顶为 t[k],次顶元素为 Table 类型的 t。第二种方法其实是第一种方法在「key 为字符串」时的特殊写法。
C API 遍历 Table
lua_getglobal(L, t);
lua_pushnil(L);
while (lua_next(L, -2)) {
/* 此时栈上 -1 处为 value, -2 处为 key */
lua_pop(L, 1);
}
lua_next 函数针对 -2 处(参数指定)的 Table 进行遍历。弹出 -1 处(栈顶)的值作为上一个 key(为 nil 时视为请求首个 key),压入 Table 中的下一个 key 和 value。返回值表示是否存在下一个 key。
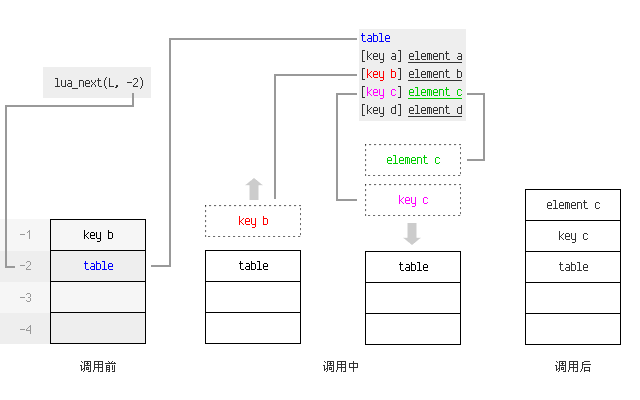
另外在循环中处理值时要记得随时清理栈,否则 Table 就不在 -2 了。(也可以考虑在 lua_getglobal 后用 lua_gettop 存下 Table 的正数索引。)
虽然这是手册中记载的遍历方法,但这种方法在遍历时并没有一定的遍历顺序,于是便又有了下面的方法。
用整数 Key 进行并不那么完美的遍历
lua_getglobal(L, t);
len = lua_objlen(L, -1);
for (i = 1; i <= len; i++) {
lua_pushinteger(L, i);
lua_gettable(L, -2);
/* 此时栈顶即为 t[i] 元素 */
lua_pop(L, 1);
}
这种方法无视了非整数 key,但可以保证遍历顺序。如果只关注整数 key,可以考虑用这种遍历方法 :)
什么东西一旦追求起效率来最终还是要归到比较底层的操作,比如 GDI 中直接操作位图数据就要用 GetDIBits / SetDIBits(或者已经废弃的 GetBitmapBits / SetBitmapBits)。因为最近要处理的都是 GDI 处理不了的 PNG 格式图片,所以还是用上了 GDI+。GDI+ 中直接操作 Bitmap 的数据就要用 LockBits / UnlockBits 了。
第一眼看见 Bitmap::LockBits 的声明我就比较晕:
Status LockBits(const Rect *rect,
UINT flags,
PixelFormat format,
BitmapData *lockedBitmapData
);
不过说实话,整个 GDI+ 库的风格相对于 M$ 的其它库来说已经是很清新脱俗了 :)
rect- 要锁定的矩形区域,一般都是锁定整个图像大小。(吐槽:为神马不能传
NULL 进去表示全图啊~)
flags- 锁定区域要进行读操作还是写操作,以及是否自己分配缓冲区。(看着比较不顺眼的
UINT 类型可取的值其实是 enum)
format- 锁定区域所需的像素格式,如果和图片本身的格式不符,GDI+ 会自动进行转换。
lockedBitmapData- 输出锁定区域信息,成员变量
Scan0 会指向被锁定的像素区域(如果 flags 里指定自己分配缓冲区的话,系统只是往 Scan0 所指缓冲区写数据)。
那么锁定全图进行读操作就是:
int w = bmp->GetWidth();
int h = bmp->GetHeight();
BitmapData bmpData;
bmp->LockBits(Rect(0, 0, w, h), ImageLockModeRead, PixelFormat32bppARGB, &bmpData);
锁定完图像区域,就可以对得到的 BitmapData 进行操作了。BitmapData 包含了被锁定区域的长、宽、格式、指针信息。取坐标 (x, y) 的像素颜色可以用:
unsigned int *pData = reinterpret_cast<unsigned int *>(bmpData.Scan0);
int stride = bmpData.Stride;
unsigned int color = pData[y * stride / 4 + x]; // color= 0xAARRGGBB
有一个比较特别的 Stride 成员,它表示「一行」图像对应的缓冲区所实际占用的字节数(因为位图文件有一条变态的规则:图片数据在存储时每一行字节数必须是 4 的倍数,如果真实图片数据宽度不是 4 的倍数则需要用垃圾数据补齐不足的字节数,于是就造成了 Stride ≠ Width 的现象,即所谓的字节对齐)。
对于图片数据操作完以后要记得对锁定区域进行解锁:
bmp->UnlockBits(&bmpData);
这样一来就功德圆满了。
嗯~这段笔记就是这样,这真是有意义的一天啊~
自己提供缓冲区
咳咳~距刚刚写这篇东西已经有大半年了,在仔细看 GDI+ 的文档时又发现了些有用的东东。
正如你所看到的,上边所说的「LockBits → 读写 bmpData.San0 → UnlockBits」的三部曲其实并不与 GDI 中的 GetDIBits / SetDIBits 完全对应。至少后者是直接从位图中读取数据到我们自己提供的颜色缓冲区、直接从自己的颜色缓冲区写到位图中去,而前者却需要在 Lock 后一行一行、甚至一个像素一个像素地手动交换。
好消息是 Bitmap::LockBits 的 flags 参数除了可以传入 ImageLockModeRead 和 ImageLockModeWrite 外还可以同时或上一个 ImageLockModeUserInputBuf。这个标志位表示让 LockBits 使用我们传入的 BitmapData 中的缓冲区信息来进行读写,而不是由它来分配、我们来读写。
举个栗子 :)
#define BPP_ARGB 4 // ARGB 每像素所占字节数
int w = bmp->GetWidth();
int h = bmp->GetHeight();
unsigned char *buffer = new unsigned char[w * h * BPP_ARGB]; // 缓冲区
BitmapData bmpData;
bmpData.Width = w;
bmpData.Height = h;
bmpData.Stride = w * 4; // 缓冲区每行大小,自行分配,每行就没有多余字节了
bmpData.Scan0 = buffer;
bmpData.PixelFormat = PixelFormat32bppARGB;
bmpData.Reserved = NULL;
bmp->LockBits(Rect(0, 0, w, h),
ImageLockModeRead | ImageLockModeUserInputBuf,
bmpData.PixelFormat,
&bmpData);
bmp->UnlockBits(&bmpData); // 此时 buffer 中即为 bmp 的颜色数据
OmniComplete 并不是插件的名字,而是 Vim 众多补全方式中的一种(全能补全)。说白了 OmniComplete 其实就是根据光标前的内容猜测光标后的内容,具体怎么猜取决于所采用的脚本。
而 OmniCppComplete 就是专为 C/C++ 编写的 OmniComplete 一个补全脚本。
那么经常和 OmniCppComplete 一起出没的 Ctags 又是什么呢?Ctags 全名 Exuberant Ctags,是一个独立的程序(也就是说,其实和 Vim 一点关系都没有)。它可以为各种语言的源代码生成语言元素(language object)索引文件。对于 C/C++ 来说,就是把源代码中的各种宏、函数、类、类成员等等元素和它们的相关信息生成索引文件,供其它程序使用。
OmniCppComplete 脚本就是根据 Ctags 生成的索引文件进行补全的。
好了,背景知识就是这样,安装步骤如下:
安装 Ctags
- 从官网下载 Ctags 可执行文件,网站是 http://ctags.sourceforge.net/
- 将下载到的文件(仅 EXE 文件即可)解压到一个目录,例如
D:/ctags
- 将该目录加入环境变量
PATH
准备索引文件
以生成 C++ 标准库索引文件为例:
- 下载专为 Ctags 修改过的 libstdc++ 头文件
- 将其解压到一个目录,例如
D:/ctags/cpp_src
使用命令行进入 D:/ctags/cpp_src 后执行:
ctags -R --sort=1 --c++-kinds=+p --fields=+iaS --extra=+q --language-force=C++ -f cpp .
建议将上一步生成的 D:/ctags/cpp_src/cpp 文件放到一个专门放置索引文件的目录以便后面的统一设置,例如放到 D:/ctags/tags
其它库的索引文件也可以依法炮制,只需切换到该库的 include 文件夹,执行:
ctags -R --sort=yes --c++-kinds=+p --fields=+iaS --extra=+q --language-force=C++ -f <文件名> .
安装 OmniCppComplete
- 下载 OmniCppComplete
- 将下载到的文件解压到
~/.vim (unix) 或者 %HOMEPATH%\vimfiles (Windows) 文件夹
- 在 vimrc 文件中加入
" ctags 索引文件 (根据已经生成的索引文件添加即可, 这里我额外添加了 hge 和 curl 的索引文件)
set tags+=D:/ctags/tags/cpp
set tags+=D:/ctags/tags/hge
set tags+=D:/ctags/tags/curl
" OmniCppComplete
let OmniCpp_NamespaceSearch = 1
let OmniCpp_GlobalScopeSearch = 1
let OmniCpp_ShowAccess = 1
let OmniCpp_ShowPrototypeInAbbr = 1 " 显示函数参数列表
let OmniCpp_MayCompleteDot = 1 " 输入 . 后自动补全
let OmniCpp_MayCompleteArrow = 1 " 输入 -> 后自动补全
let OmniCpp_MayCompleteScope = 1 " 输入 :: 后自动补全
let OmniCpp_DefaultNamespaces = ["std", "_GLIBCXX_STD"]
" 自动关闭补全窗口
au CursorMovedI,InsertLeave * if pumvisible() == 0|silent! pclose|endif
set completeopt=menuone,menu,longest
另外,还需确认在 vimrc 中开启了 filetype 选项,不然 OmniComplete 无法自动识别 C/C++ 文件类型进行补全。
这样,在插入模式编辑 C/C++ 源文件时按下 . 或 -> 或 ::,或者手动按下 Ctrl+X Ctrl+O 后就会弹出自动补全窗口,此时可以用 Ctrl+N 和 Ctrl+P 上下移动光标进行选择。
美化咩?
也许你也已经注意到了一个问题,那就是「自动补全窗口的配色非常之丑」,Vim 自带的几个配色方案中只有两三种配色改掉了自动补全窗口丑陋的紫色,其它的基本上都是很逆天的用灰色表示当前选中项、紫色表示其他项。
要改变自动补全窗口的配色可以在 vimrc 中加上:
highlight Pmenu guibg=darkgrey guifg=black
highlight PmenuSel guibg=lightgrey guifg=black
Pmenu 是所有项的配色,PmenuSel 是选中项的配色,guibg 和 guifg 分别对应背景色和前景色。
标题用中文写觉得比较怪(用字符串作为数组下标),那就写英文吧~
话说前几天人人网 C 语言公共主页发了篇日志,内容是腾讯的面试题:
int a = 3, b = 5;
printf(&a["Hi!Hello"],&b["fun/super"]);
printf("%c%c%c%c",1["wst"],2["www"],0["ddd"],5["ewewrew"]);
这段代码应该输出什么呢?答案是应该输出:
Helloswde
主页君说没遇到过这类语法,于是把编译后的程序反汇编了说明为什么是这个答案。
但事实上,类似 a["Hi!Hello"] 的语法和普通数组 a[3] 的用法并没有什么两样。
我们知道,C 语言的数组直接对应一片连续的内存,数组名代表起始地址,要访问数组元素就要用方括号中的表达式代表该元素的偏移量。类似 array[index] 的表达式实际上等价于
*(array + index)
由于指针算术(Pointer Arithmetic)的关系,表达式可以正确得到 array 指针向后指 index 个元素的值(前提是 array 和 index 两者中有且只有一个指针,否则该表达式无效)。所以 array[index] 和 index[array] 其实没什么两样。
那么,既然 C 语言字符串本质是字符数组的首地址,3 + "Hi!Hello" 就是一个指向字符串3号元素的字符指针,传给 printf 即从第4个字符开始输出到 '\0'。
所以说,这道面试题其实是非常巧妙的基础题。但悲催的是,那篇日志下的评论不少是“考这个有鸟用”、“TX就会这种傻逼题”、“考这么偏的点”,真是让人感到悲哀……
- «
- 1
- ...
- 13
- 14
- 15
- 16
- 17
- 18
- »
